Backpropagation: Understanding The Heart of Deep Learning

How does a computer really learn?
What does it mean for a computer to learn?
These are thought-provoking questions that are answered when you dive deep into the subject of deep learning. This article will serve as a first taste to the backpropagation algorithm, and the concept of gradient descent; which is what enables computers to learn.
Some Context
This article goes into detail about a specific part of deep learning, so it is important to clarify where we are on the “artificial intelligence map”. Artificial Intelligence is a broad field in which Machine Learning is a subset of, and Deep Learning is a subset of that.
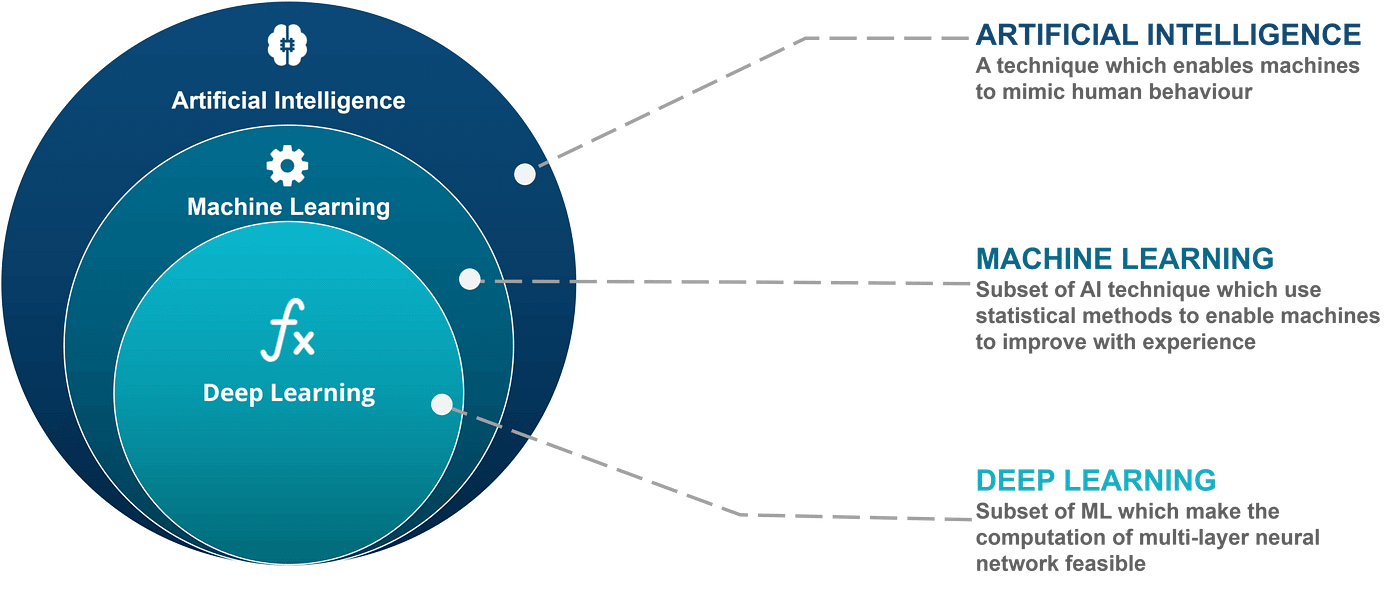
Deep learning is focused on using artificial neural networks to classify inputs. There are many types of neural networks but the simplest one is the multilayer perceptron. This is the neural network I will use to describe backpropagation.
Let me quickly explain what a multilayer perceptron network is. The network is comprised of layers each made up of neurons(a thing that holds a value). The network contains at least 3 layers. The first layer is your input, say pixels in an image. The last layer is what you believe those inputs were, say identifying the pixels were in the shape of the number. And the middle layers are where you piece the inputs together before classifying what they are as a whole in the last layer.

The neurons are all connected together, as shown by the image above. When one neuron in the first layer has a value it affects the value of a neuron in the next layer. The magnitude of this effect is determined by weights and biases. Weights determine how strong each connection is, and biases are like the minimum required value to have any effect on the next neuron.
Changing the weights and biases are what gives the network its “intelligence”. If the network has the right weights and biases, it essentially understands which connections to which inputs matter most. Changing the weights and biases is done by the heart of the article today, backpropagation.
Backpropagation and Gradient Descent
How do we determine how to change the weights and biases? Well, first we must understand what was wrong with the network in order to make it correct. This is done by the cost function. This cost function compares the output of the network to what it should actually be. The idea is to minimize this so that eventually the network is always outputting the correct output.
This is where we come to gradient descent. We think of the cost function as a multivariable function, with each variable being its own separate weight. With huge neural nets, this number can huge! To make it easier to visualize it is better to think of it as having only two inputs.

The output of this function is a 3-dimensional graph. The goal is to find the local minimum by finding the direction of the steepest descent. By finding the “valley” of this “hill” it represents the cost function getting smaller which means an improvement in the accuracy of our neural net.
To find the slope that is the steepest decline we find the negative gradient, which is a multivariable calculus concept calculated by our backpropagation algorithm. You don’t have to fully understand multivariable calc to understand gradient descent, but it is important to understand that it underlays the technology.
The Algorithm
How does this algorithm work? The algorithm compares the network output layer and its activations to what it is supposed to really be (someone has to go before and classify the data, and what the output was supposed to be, ex. classify a 2 as a 2). It goes neuron by neuron and checks how it compares to the correct output.

If it is different it sees how it can change the weights, biases, or activations in the last layer. This is done for all the neurons that are connecting to that one neuron and repeated for all neurons and layers. An aggregate of the changes that should be made to the weights and biases is calculated and the weights and biases are changed for the next dataset.

What comes from the backpropagation algorithm is a vector with a change for every weight and bias in the neural net. Over time and many training data examples, the network can become extremely accurate at classifying numbers.
There are some limitations, notably that it could never be better than humans at this task. This is where a new type of deep learning called unsupervised learning comes into play. There is so much to dig into this field and so many applications that it is a really exciting time to be an ML enthusiast!
This was my first article on an academic-related topic and I hoped you enjoyed it. I would suggest if you are interested in learning more about deep learning to watch this series by 3blue1brown on the topic.
